Home
AI Tools
AI Porn Generators
Porn GIF Generators
Porn Video Generators
Futanari Generators
AI Girlfriend Sexting Bots
Hentai Anime Generators
Porn Image Generators
Uncensored GPT Chat Alternatives
Erotic Story Generators
Deepfake Porn Generators
AI Nudifier & Undresser Apps
Porn Face Swap Generators
Unlock My Fantasy
All Tools
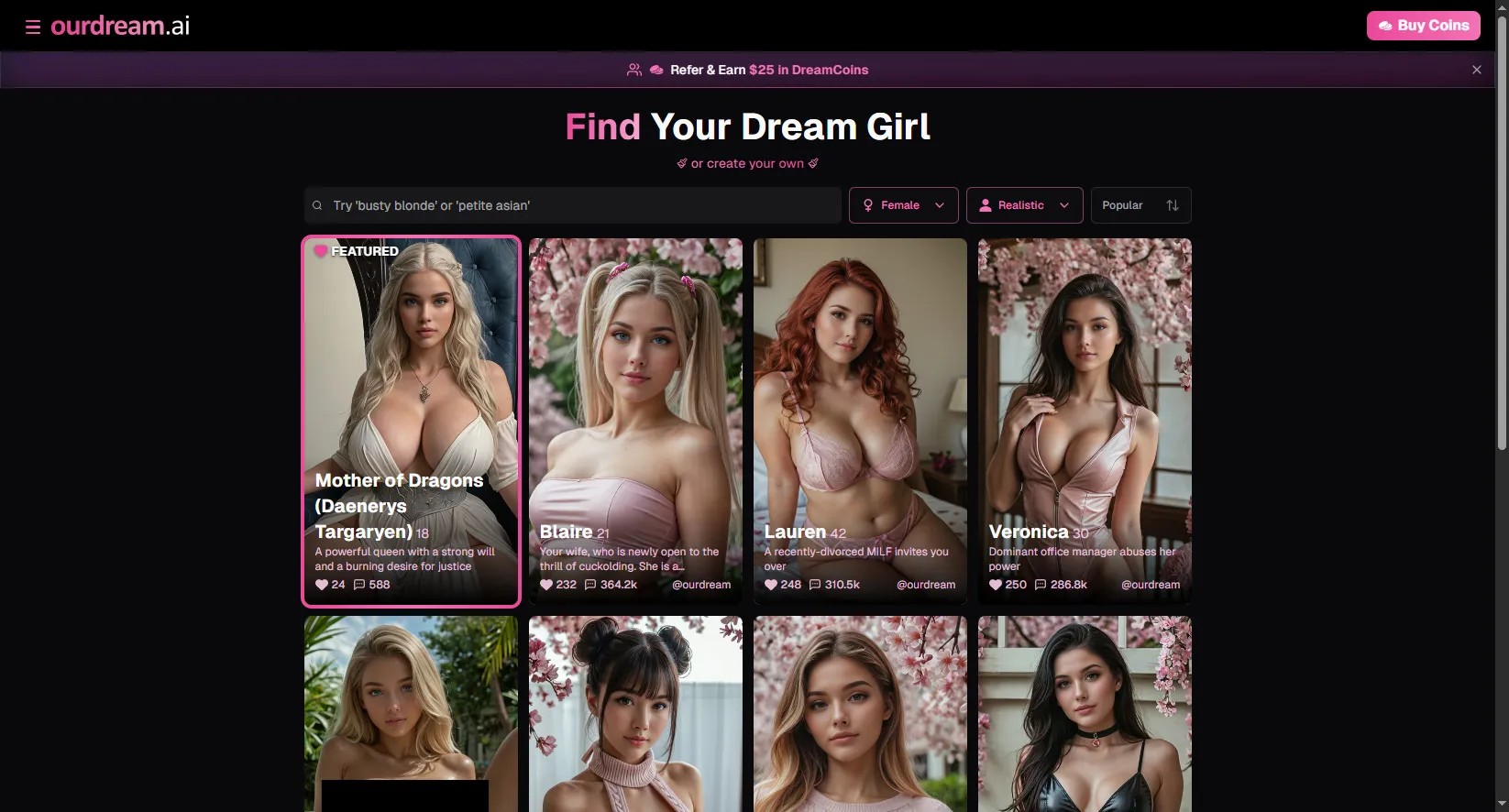
Ourdream.ai
See Details →
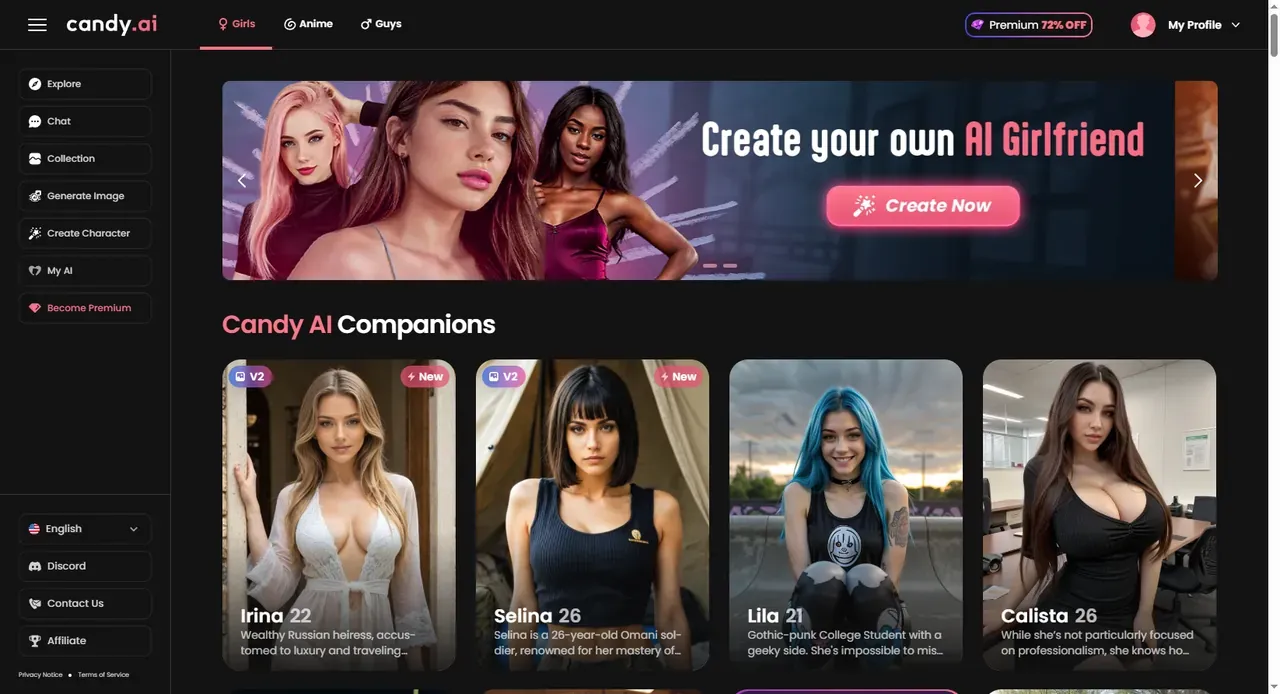
Candy.ai
See Details →
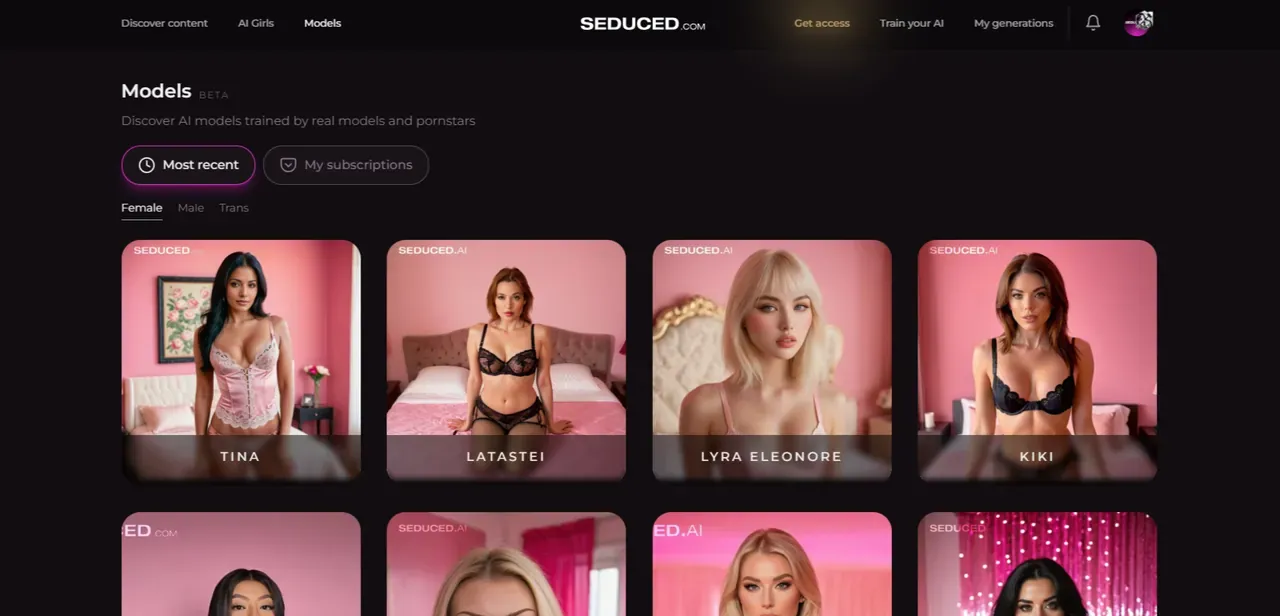
Seduced
See Details →
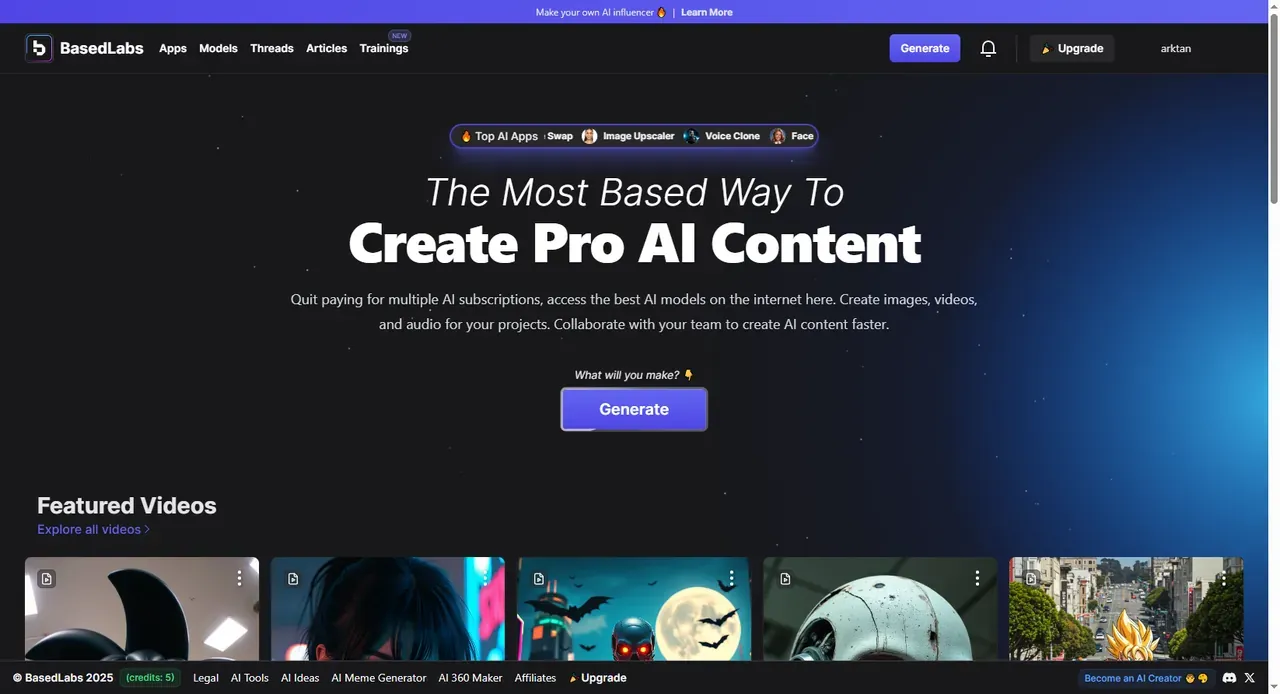
BasedLabs
See Details →
Alice AI
See Details →
Secret Desires
See Details →
Spicychat.ai
See Details →
Dream GF
See Details →
SwapFans
See Details →
AI Nudez
See Details →
Undress AI App
See Details →
UndresswithAI
See Details →
1
2
3
4
5
Next
Our Top Ranked AI Tools
Candy.ai
See Details →
Porn Video Generators
Ourdream.ai
See Details →
Futanari Generators
PornWorks AI
See Details →
AI Nudifier & Undresser Apps
Seduced
See Details →
Hentai Anime Generators